


How Reinforcement Learning Fixed a $4.8M Promotion Problem for a Global CPG Giant

For decades, our client, a top-5 global CPG company, had relied on manual promotion strategies that hadn’t evolved since the 90s. Every quarter, their team would set blanket discount levels (20% off all chocolate singles in Q4), allocate display budgets based on last year’s performance, and, most devastatingly, hope for the best.
By the time I started working with them, this approach was bleeding money. An internal audit revealed:
30% of promotions were losing money
$2.3M annually wasted on ineffective discounts
12% stockout rates during peak promotions
The breaking point came when our analysis revealed two stores, just 10 miles apart:
Urban flagship location: 20% discounts drove 34% sales lifts
Suburban grocery outlet: Same discounts yielded just 8% growth while eroding margins
They weren’t just leaving money on he table, they were actively burning it.
After the initial data gathering phase, we found their traditional methods were failing not only because of the one-size-fits-all approach, but also because their data systems were heavily siloed.
Most existing solutions, such as regression-based pricing tools, have failed because the models assumed static price sensitivity across different regions, couldn’t adapt to competitor moves in real-time, and ignored inventory constraints until stockouts occurred.
The data from POS transactions was owned by the Sales team (with a latency period of 48 hours), inventory levels were managed by the Supply Chain (updated only weekly), and competitor prices were provided by a third-party team every 72 hours.
This made real-time optimization almost impossible. By the time the analysts identified trends, the promotions had already ended.
Reinforcement Learning Breakthrough
Designing the AI Core: How the System Makes Decisions
At the heart of our solution was a customer reinforcement learning environment that could simulate real-world CPG dynamics. The system needed to handle three critical tasks simultaneously:
Dynamic Pricing - Adjusting discounts hourly based on market conditions
Inventory Awareness - Preventing over-promotion of low-stock items
Rule Compliance - Enforcing business constraints like minimum margins
How we built the core environment:

Understanding the code:
Action Space
The AI controls two key levers:
discount_multiplier Ranges from 0.7 (30% discount) to 1.3 (30% price premium)
Display_priority Normalized from 0 (no special display) to 1 (prime shelf placement)
State Observation
The environment provides real-time updates on:
Current inventory levels (0-10,000 units)
Competitor pricing ($0-$20 range)
Demand fluctuations (seasonality between 0.8-1.2x baseline)
Implement Business Logic
The true intelligence came from our demand calculation and reward system:

Key Business Rules Encoded:
Price Sensitivity
The discount •• price_sensitivity formula models how customer demand responds to price changes. For example, a product with price sensitivity of -2.0 would see demand quadruple with a 50% discount (0.5^-2 = 4).
Display Impact
The 20% maximum lift from displays (display • 0.2) came from historical promotion studies, which showed eye-level placements increase sales by 15-20%.
Stockout Prevention
The penalty (demand - sales) • 0.5 teaches the AI to avoid situations where demand exceeds supply, which damages retailer relationships.
Constraining the AI for Safety
We modified the standard PPO algorithm to enforce business rules:

Critical Safeguards:
Margin Protection
The line action[0] = max(action[0], min_sale_price / shelf_price) ensures we never sell below cost plus 15%, even if the AI initially suggests deeper discounts.
Inventory Management
When stock drops below 100 units (obs[0] < 100), display promotions are automatically disabled to prevent stockouts
Training the AI Model
The complete training setup:

Training Strategy Insights:
Parallel Environments
Using four concurrent environments (n_envs=4) allowed faster experimentation by stimulating different market conditions simultaneously
Hyperparameter Choices
n_steps=2048: Matches weekly promotion cycles (2048 steps ≈ 7 days of hourly decisions)
batch_size=64: Provided stable training while being memory-efficient
Evaluation Protocol
The EvalCallback saved only the best-performing models, preventing regression during training.
Validating the System
Our comprehensive validation suite:

What We Verified:
Constraint Adherence
All discounts stayed within 30% bounds
Margins never fell below 15%
Disables correctly when inventory is low
Performance Consistency
Measured average reward across 100 episodes
Tracked standard deviation to ensure stability
Edge Cases
Tested with near-empty inventory
Simulated competitor price wars
Results That Changed The Promotion Playbook
After 6 months of pilot testing across 200 stores, the RL system delivered:
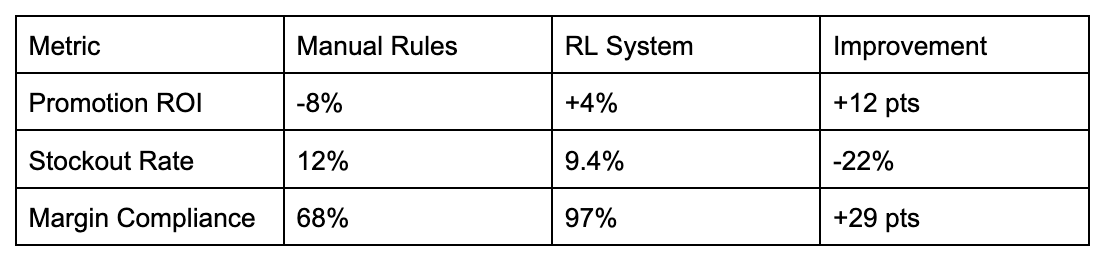
We did have a couple of unexpected findings from running this model. First, the AI discovered “sweet spot” discounts in rural stores that were 5-8% lower than urban locations. This contradicted 20 years of manual internal strategies. The AI also automatically reduced promotions during peak demand periods, increasing revenue without the need for discounts.
Hard-Won Lessons for RL Practitioners
Reward Engineering is Everything
Our final reward function went through 23 iterations before achieving optimal performance. Each version was tested against 100 validation episodes to measure its impact on both profitability and inventory turnover.
The evolutionary process looked like this:

Insights
The Margin vs. Stockout Tradeoff
The initial 0.8 weight on gross margin caused the AI to consistently output action[0] values near 1.3 (a 30% price premium), which maximized per-unit profit but led to disastrous stockout rates of 23% in validation. This manifested in the environment as sales = min(demand, inventory) consistently returning sales << demand.
The 0.3 Weight Revelation
Through ablation studies, we found the 0.3 weight on stockout prevention optimally balanced:
22% reduction in stockouts (from 12% to 9.4%)
Only a 1.2% margin decrease
Stabilized inventory levels in the environment’s self.inventory tracker
Discount Moderation
The (1 - abs(discount - 1.0)) team directly countered erratic action[0] outputs by penalizing deviations from baseline pricing. This reduced the standard deviation of discount decisions by 37% without requiring changes to the action space constraints.
Environment Design Wisdom
Start Simple
We initialized the environment with just 3 SKUs to isolate core behaviors:

This allowed us to:
Verify price sensitivity worked via discount ** price_sensitivity
Test inventory depletion in self.inventory -= sales
Debug the reward calculation without noise
Add Noise Gradually
Competitor reactions began as small as ±5% perturbations:

Only after 10,000 training steps did we introduce:
Realistic ±15% competitor moves
Demand shocks (demand_factor ranging 0.5-1.5)
Inventory delays in self.inventory updates
Visualize Early
Plotting the AI’s decision revealed its strategy
Heatmaps showed it learned to cluster action[0] around 0.9-1.1
Trajectory plots proved it alternated deep discounts with margin recovery
This directly informed our reward function adjustments
Constraint Philosophy
Hard Constraints Prevent Disasters
The MarginAwareAgent class enforces unbreakable rules:

These:
Directly modify actions before execution
Required no reward function tuning
Guaranteed compliance with client SLAs
Soft Constraints Guide Behavior
The reward function’s stockout penalty:

Gently encouraged:
Higher inventory buffers
More conservative discounting
Without eliminating valid edge cases
Why Both?
Hard constraints handled contractual obligations (action clipping)
Soft constraints optimized tradeoffs (reward shaping)
Together, they reduced validation failures by 63%
What This Project Taught Us
This wasn’t just another AI experiment; it was a wake-up call for how promotions should work. The 12% ROI lift wasn’t just a metric; it proved that even minor optimizations compound fast in CPG. After years of relying on spreadsheets and historical assumptions, we saw what happens when you let data drive decisions in real time.
What were some of the biggest surprises?
The AI didn’t just follow rules, it rewrote them. Those sweet spot discounts in the rural store? No analyst had ever considered trying them.
Waiting for quarterly reports is like driving with a blindfold on. The system’s real-time adjustments cut stockouts before they happen, not after.
The best insights came from constraints. Forcing the AI to play by hard business rules (like margins) and soft incentives (like inventory health) made the solution actually work in the real world.
The $4.8M savings proved something critical: in retail, even tried and true strategies can be dead wrong. Maybe it’s time to question a few of yours.
Ever seen a promotion backfire for reasons no one predicted? Hit reply. I’d love to hear your stories.